有鑒於昨天的實作部分,有朋友反應好像講不清楚,一下子就給 code,今天還是再針對每一個 part 來詳細說明~
通常在寫大型專案的時候,我都會先用空的 function 來梳理邏輯,避免過程中把太多功能放到同一個 function,或是寫的過程被中斷,下次回來要花很多時間 review,當然,昨天的code算是很簡單的東西,但是習慣還是從簡單的培養起會比較好~
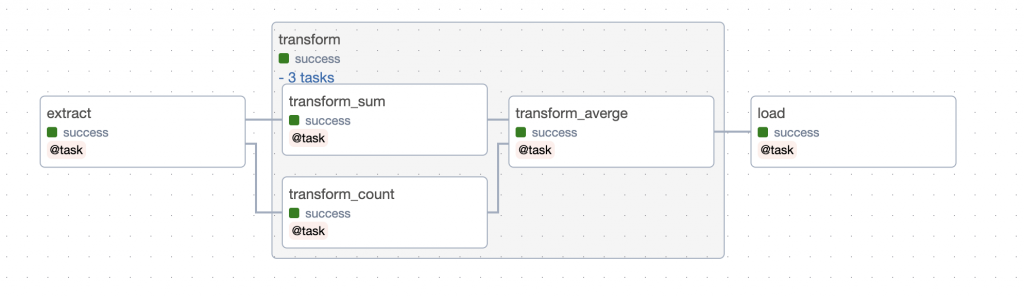
可能有些人覺得 DAG 圖是做完才會有,怎麼可能先拿到圖再開始 coding, DAG 圖當然是做完才會有(或是像前幾天用EmptyOperator來做其實也可以有😂),但是DAG 圖在做之前,其實就要自己先設計了,而且資料和程式都是自己寫,當然不會先拿到設計或流程圖啊,資料工程師又不是前端工程師,前端可以看一下 Wireframe 和設計圖去實作,資料工程師必須具備自己造水管的能力,不然身為水管工,不會設計水管架構圖就不合格了
E: 確定先用 Extract 拿到資料T: 用 Transform 修改資料,計算出需要的資料L: Load 將資料送到目的地當然這比較像是扮家家酒的 ETL,但如果能讓對於這觀念模糊的人更清楚一點點,那就夠了~
像在這部分,我們只需要知道我們會拿到訂單資料,然後處理過後會顯示出平均價格這樣就可以了
我們就可以依照想像中的流程寫出 虛擬碼 (Pseudocode),可能語法有錯都沒關係,重點是架構:
def extract():
Get data
def transform():
Do something
def load():
Show the average price
接下來詳細看我們拿到的資料:
[
{
"order_id": "1001",
"order_item": "薯餅蛋餅",
"order_price": 45
},
{
"order_id": "1002",
"order_item": "大冰奶",
"order_price": 35
}
]
我們發現是 JSON array 格式的,有點類似 Python 的 List,Array 裡面的資料很像 Python 的 Dictionary,我們的需求是要算出訂單的平均價格,所以就要想辦法拿到 Dictionary 裡面的 order_price。
import json
def extract(json_data):
data = json.load(json_data)
return data
def transform(order_data):
order_total = 0 # 加總後的結果變數
for order_dict in order_data:
order_total += order_dict['order_price'] # 用+=把每筆order的價格加到order_total
order_count = len(order_data) # len直接拿到 order_data_json的數量
order_average = order_total/order_count # 總價格/數量=平均價格
return order_average
突然,我們發現這隻 Transform 不符合 function SOLID 的單一職責原則(Single Responsibility Principle),所以我們決定把 function 拆開(哈哈哈硬要誒
)
def transform_sum(order_data_json):
order_total = 0
for order_dict in order_data_json:
order_total += order_dict['order_price']
return order_total
def transform_count(order_data_json):
order_count = len(order_data_json)
return order_count
def transform_averge(order_total, order_count):
order_average = order_total/order_count
return order_average
每個function只做一件事了,耶~~
為了等等能用 TaskGroup,只能忍耐了
def load(order_average):
print(f"Average Order Price: {order_average}")
@dag(schedule_interval=None, start_date=datetime(2023, 9, 28))
def taskflow_etl_dag():
pass
可以直接用一行去設定dag相關資訊,開始時間、排程、名稱等等,用 @dag 會預設 function 名稱就是 dag_id ,不用自己設定,也不用怕不小心設定不一樣,真是太好了~
@task()
def extract(json_data):
data = json.load(json_data)
return data
直接在前面加上 @task,這個 python function 就會變成 pythonOperator 的 task 了,可以在後面括號設定細節,不設定會用 function 名稱就是 task_id
@task_group
def transform(order_data):
task_group的部分是可以把多個task放在一起,詳細介紹可以看前幾天的貼文,@task_group 也是一樣在function 前面加上就可以了
還記得嗎?虛式·茈就是蒼加上赫,誒~只有我有看嗎,反正了解了邏輯架構和語法細節之後,只要把語法放到架構裡面去寫,基本上就能順利完成,但大多時候都不一定順利
@dag(schedule_interval=None, start_date=datetime(2023, 9, 27))
def taskflow_etl_dag():
@task()
def extract():
xxx
@task_group
def transform(order_data):
@task()
def transform_sum(order_data_json):
xxx
@task()
def transform_count(order_data_json):
xxx
@task()
def transform_averge(order_total, order_count):
xxx
order_average_result = transform_averge(
transform_sum(order_data), transform_count(order_data))
return order_average_result #要執行並回傳
@task()
def load(order_average):
xxx
load(transform(extract()))
taskflow_etl_dag()
設定 task_group 當中的相依性order_average_result = transform_averge(transform_sum(order_data),transform_count(order_data))
這就像之前學的[transform_sum,transform_count] >> transform_averge
但是用taskflow api 就是要用 function return 來做設定
設定 整體的順序:load(transform(extract())) 等同於之前的 extract >> transform >> load
這當中最需要注意的是在 task_group 當中的 task 盡量要在裡面執行並回傳,邏輯上會比較清晰,如果要在外面使用,代表其實就要重新思考這個 task 應不應該放在 task_group 當中。
完整的 code 請回昨天查看喔!!
五條老師不要走~今天用了另一種方式說明和昨天相同的 code,希望大家看完能夠清楚,明天真的要用docker了~預祝中秋節快樂,放完假胖5公斤



 iThome鐵人賽
iThome鐵人賽